GuideMe Dataset
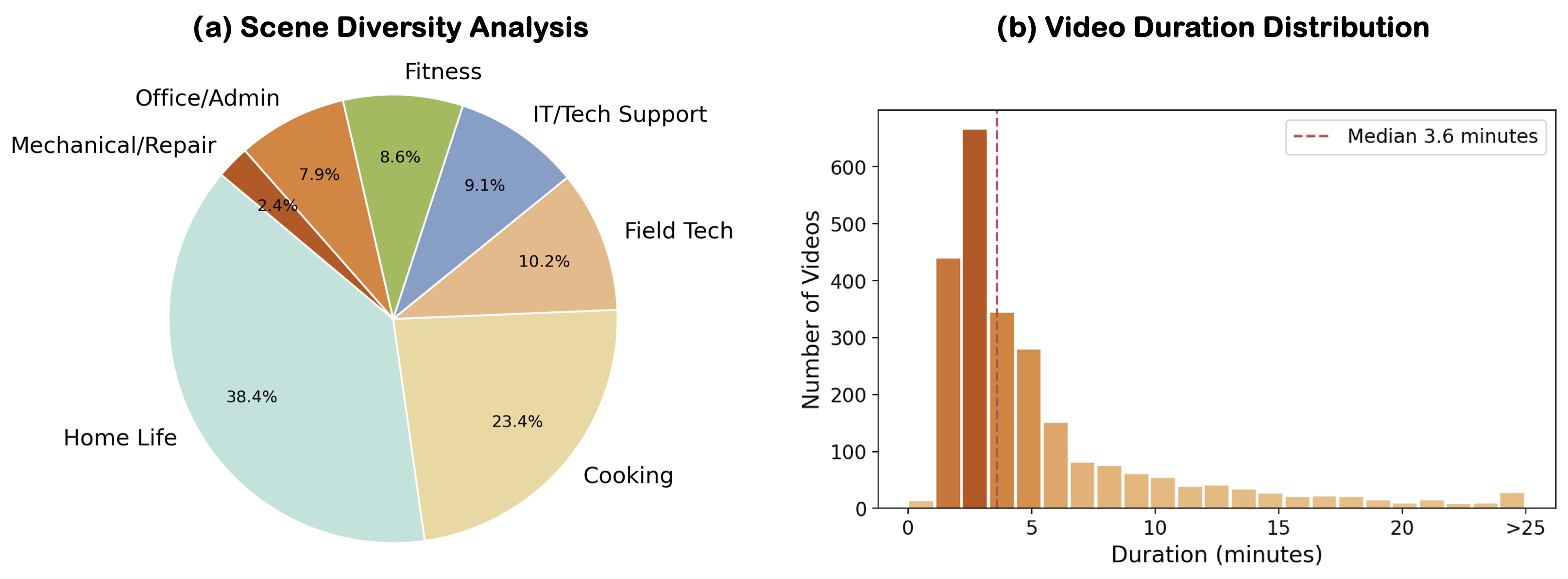
The final dataset contains 2,458 video instances with a combined duration of 223.7 hours. Video lengths range from 0.5 to 41.2 minutes (average 5.5 min, median 3.6 min), yielding 47,775 streaming interaction samples across cooking, daily tasks, fitness, and embodied assistance, of which 9,876 form the held-out test set used for all evaluations. GuideMe is split into GuideMe-Train (1,985 videos, 177.0 hours) and GuideMe-Test (473 videos, 46.7 hours); all reported evaluations use GuideMe-Test, while GuideMe-Train supports task-specific adaptation and is used only for the fine-tuned Qwen3-VL-8B result in the main results table.
| Dataset | Domain | #Videos | Hours | Step-level Instruction | Timed Feedback | Error Detection | Action-specific Correction | Closed-loop Interaction |
|---|---|---|---|---|---|---|---|---|
| Epic-Kitchen-100 | Cooking | 700 | 100 | ✓ | × | × | × | × |
| COIN | Diverse | 11,827 | 476 | ✓ | × | × | × | × |
| HoloAssist | Object Manip. | 2,221 | 166 | × | × | ✓ | ✓ | × |
| CaptainCook4D | Cooking | 384 | 94.5 | × | × | ✓ | × | × |
| QEVD-Fit-Coach | Fitness | 223 | 13.5 | ✓ | ✓ | ✓ | ✓ | × |
| Assembly101 | Assembly | 4,321 | 513 | × | × | ✓ | ✓ | × |
| EgoPER | Cooking | 386 | 28 | ✓ | × | ✓ | × | × |
| GuideMe | Diverse | 2,458 | 223.7 | ✓ | ✓ | ✓ | ✓ | ✓ |
Comparison of procedural video datasets. GuideMe supports closed-loop interactive task guidance across all five evaluation dimensions.
Domain Distribution
GuideMe bridges everyday routines and more complex assistance scenarios. Home Life and Cooking form the largest portion of the benchmark, accounting for 38.4% and 23.4% of the videos, while technical domains such as Field Tech and IT Support contribute 38.2%.
Duration Distribution
The videos range from 0.5 to 41.2 minutes, with an average duration of 5.5 minutes and a median of 3.6 minutes. This distribution covers concise step-level tasks while retaining long-form sequences for evaluating long-range temporal reasoning.