Method Overview
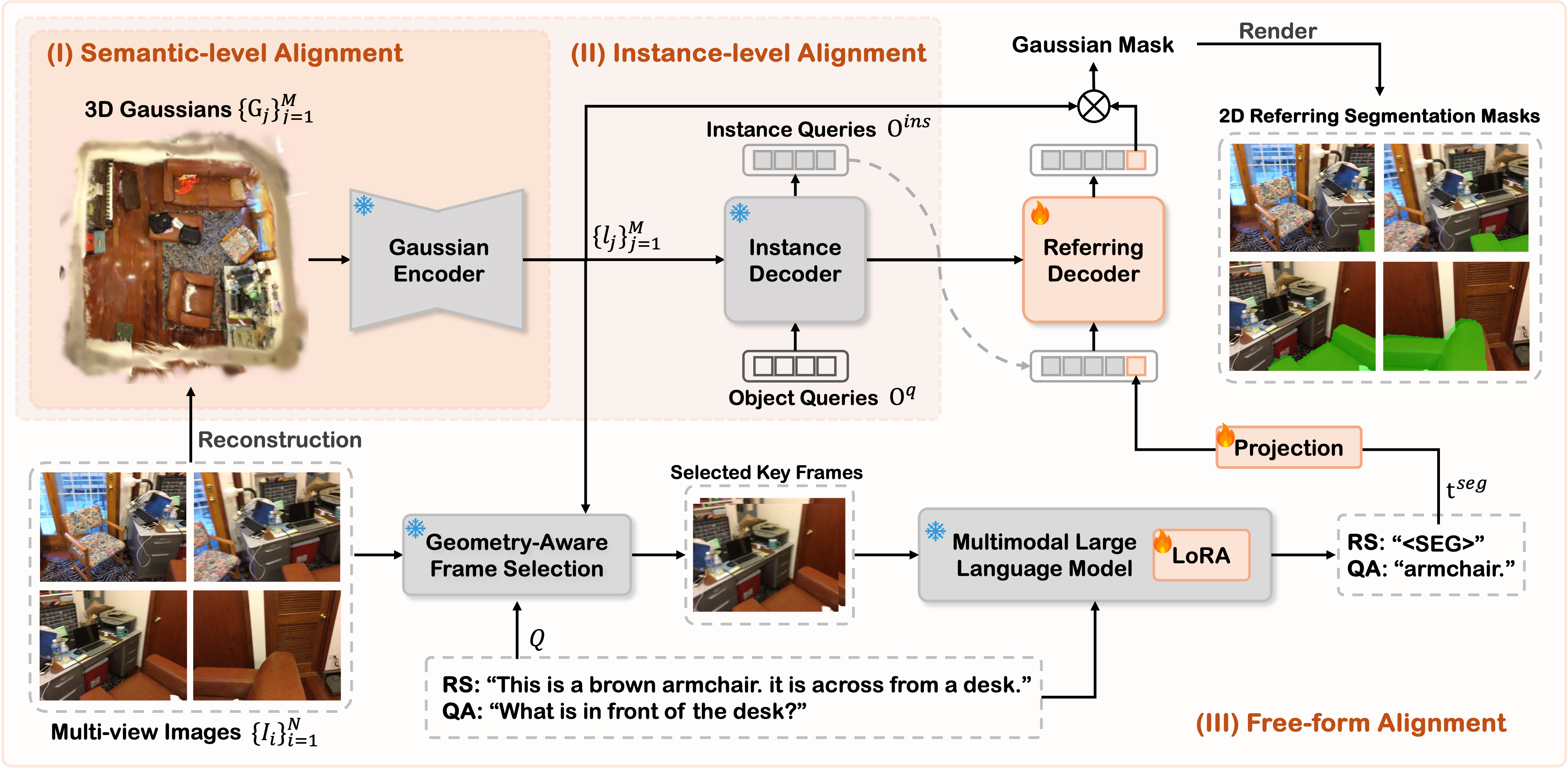
Overview of the GenSplat framework. Given multi-view RGB images and a text query (e.g., for Referring Segmentation or VQA), GenSplat first reconstructs a 3D Gaussian representation and extracts semantic Gaussian features via the Gaussian Encoder, based on which the Instance Decoder produces instance queries for 3D segmentation. Meanwhile, a Geometry-Aware Frame Selector (GAFS) adaptively selects informative keyframes. The text and selected frames are processed by a MLLM to predict a reasoning token for referring segmentation (or generate answering tokens for VQA). The generated token is concatenated with instance queries and fed into the Referring Decoder to generate the corresponding 3D Gaussian mask.

